智能体介绍#
数据处理智能体#
负责与 Data-Juicer 交互,执行实际的数据处理任务。支持从自然语言描述自动推荐算子、生成配置并执行。
工作流程:
当用户说:"我的数据保存在 xxx,请清理其中文本长度小于5、图片大小小于10MB的条目",Agent 并不会盲目执行,而是按步骤推进:
数据预览:预览前 5–10 个数据样本,确认字段名和数据格式——这是避免配置错误的关键一步
获取签名:调用
get_ops_signature工具,获取算子参数签名及简单描述参数决策:LLM 自主决定全局参数(如 dataset_path、export_path)和算子具体配置
配置生成:生成标准的 YAML 配置文件
执行处理:调用
dj-process命令执行实际处理
整个过程既自动化,又具备可解释性。用户可以在任何环节介入干预,确保结果符合预期。
典型用途:
数据清洗:去重、移除低质量样本、格式标准化
多模态处理:同时处理文本、图像、视频数据
批量转换:格式转换、数据增强、特征提取
查看完整示例日志(from AgentScope Studio)
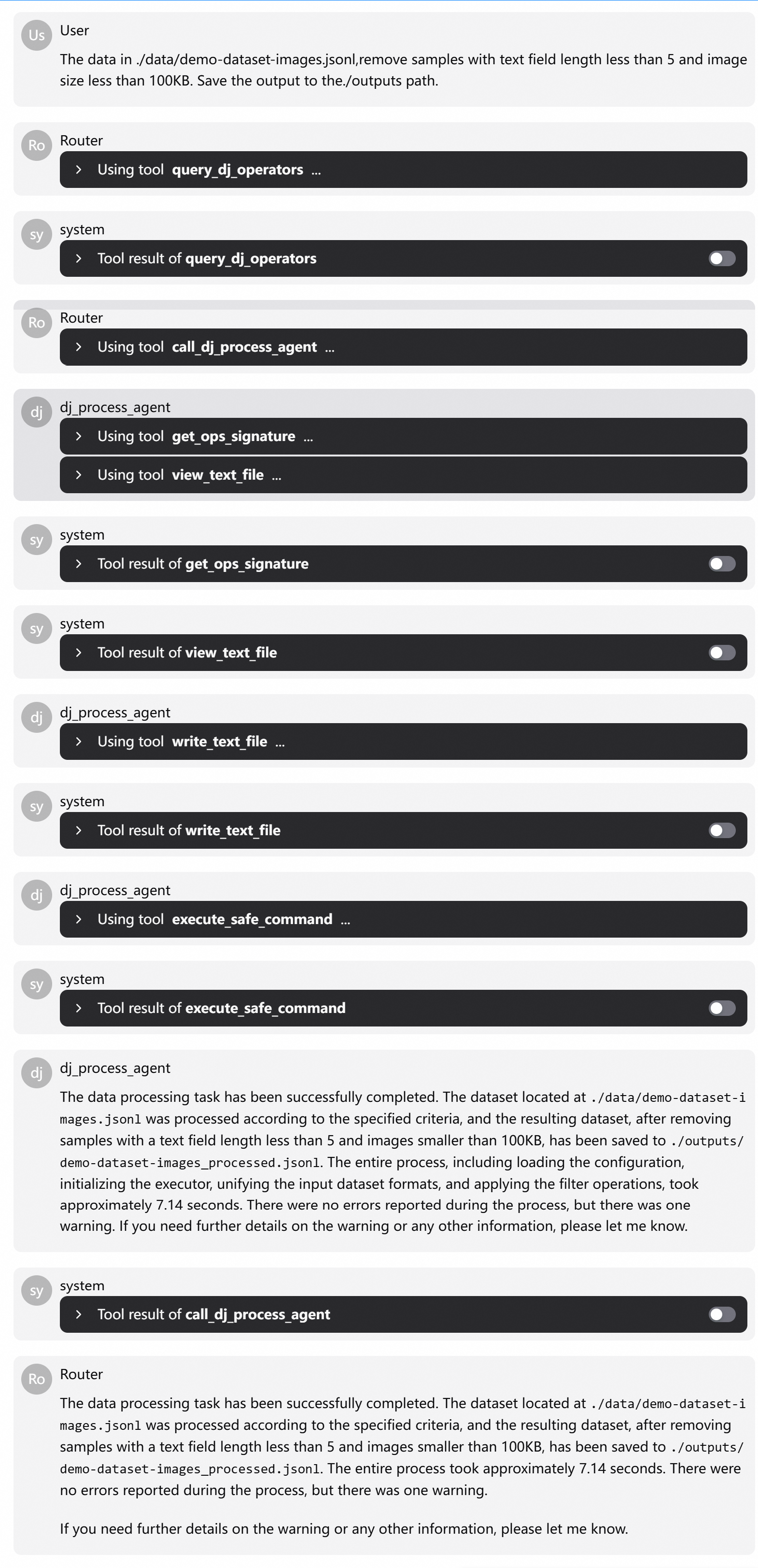
示例执行流程:
用户输入:"The data in ./data/demo-dataset-images.jsonl, remove samples with text field length less than 5 and image size less than 100Kb..."
路由:调用 query_dj_operators,精准返回两个算子 text_length_filter 和 image_size_filter
数据处理 Agent 执行步骤:
调用
get_ops_signature,获取text_length_filter和image_size_filter的参数签名用
view_text_file工具预览原始数据,确认字段确实是 'text' 和 'image'生成 YAML 配置,并通过
write_text_file保存到临时路径调用
execute_safe_command执行dj-process,返回结果路径
整个过程没有人工干预,但每一步都可追溯、可验证。这正是我们追求的"自动化但不失控"的数据处理体验。
代码开发智能体#
当内置算子无法满足需求时,传统做法是:查文档、抄代码、调参数、写测试——整个过程可能耗时数小时。
Operator Development Agent 的目标,是将这个过程压缩到几分钟,并保证代码质量。默认使用 qwen3-coder-480b-a35b-instruct 模型驱动。
工作流程:
当用户提出:"帮我创建一个将单词倒序排列的算子,并生成单元测试文件",Router 会将其路由至 DJ Dev Agent。
该 Agent 的执行流程分为四步:
获取参考算子:查找功能相似的现有算子作为参考
获取模板:拉取基类文件和典型示例,确保代码风格一致
生成代码:基于用户提供的函数原型,生成符合 DataJuicer 规范的算子类
本地集成:将新算子注册到用户指定的本地代码库路径
整个过程将模糊需求转化为可运行、可测试、可复用的模块。
生成内容:
实现算子:创建算子类文件,继承 Mapper/Filter 基类,使用
@OPERATORS.register_module装饰器注册更新注册:修改
__init__.py,将新类加入__all__列表编写测试:生成覆盖多种场景的单元测试,包括边缘 case,确保鲁棒性
典型用途:
开发领域特定的过滤或转换算子
集成自有的数据处理逻辑
为特定场景扩展 Data-Juicer 能力
查看完整示例日志(from AgentScope Studio)
